What are the dplyr () Package functions in R for Joining Datasets
Like SQL Joins, in R also we can perform various Joins on the Datasets as below using the dplyr () Package. Currently dplyr supports four types of mutating joins and two types of filtering joins.

 > library(dplyr)
> library(dplyr)
inner_join() :
To join by different variables on x and y use a named vector. For example, by = c("a" = "b") will match x.a to y.b.



Now we can group by and summarize this joined data as follows..
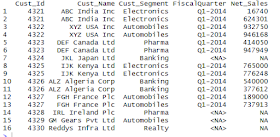
>dtCust %>%
inner_join(select(dtSales,Cust_Id,FiscalQuarter,Net_Sales),by="Cust_Id",copy=F) %>%
group_by(Cust_Id,Cust_Name,Cust_Segment,FiscalQuarter) %>%


 II.Filtering joins ::
II.Filtering joins ::
The semi_join() function returns all rows from x where there are matching values in y, and keeping just columns from x.A semi join differs from an inner join because an inner join will return one row of x for each matching row of y, where a semi join will never duplicate rows of x.
Syntax:
semi_join(x, y, by = "KeyVariable", copy = FALSE, …)
Example :
Now we will do Semi Join the above two datasets using the semi_join() function as follows..

anti_join(x, y, by = "KeyVariable", copy = FALSE, …)
Now we will do Semi Join the above two datasets using the anti_join() function as follows..

 >dtSales2
>dtSales2
 Note : From the both the datasets, we observed that 2 observations are duplicated.
Note : From the both the datasets, we observed that 2 observations are duplicated.




Like SQL Joins, in R also we can perform various Joins on the Datasets as below using the dplyr () Package. Currently dplyr supports four types of mutating joins and two types of filtering joins.
Now we will discuss about all the Joins using the following data sets.
Left Dataset (dtCust)

Right Dataset ( dtSales)

I. Mutating Joins ::
Mutating joins combine variables from the two dataframes. inner_join() :
The inner_join() function return all rows from x where there are matching values in y, and all columns from x and y. If there are multiple matches between x and y, all combination of the matches are returned.
Syntax :
inner_join(x, y, by = "KeyVariable", copy = FALSE, suffix = c(".x", ".y"), …)
Arguments() :
x, y : datasets to join.
by : a character vector of variables to join by. If NULL, the default, *_join() will do a natural join, using all variables with common names across the two tables.To join by different variables on x and y use a named vector. For example, by = c("a" = "b") will match x.a to y.b.
copy : If x and y are not from the same data source, and copy is TRUE, then y will be copied into the same source as x.
This allows you to join tables across sources, but it is a potentially expensive operation so you must opt into it.
suffix : If there are non-joined duplicate variables in x and y, these suffixes will be added to the output to disambiguate them. Should be a character vector of length 2.
… : other parameters passed onto methods, for instance, na_matches to control how NA values are matched.
Example :
Now we will do Inner Join the above two datasets using the inner_join() function as follows..
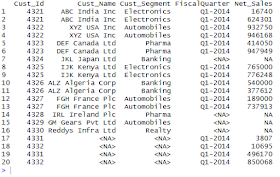
> inner_join(dtCust,dtSales,by="Cust_Id",copy=F,suffix=c("_L","_R"))
If the KeyVariable name is different in Right dataset then specify them as follows..
> inner_join(dtCust,dtSales,by=c("Cust_Id"="CustId),copy=F,suffix=c("_L","_R"))
Notes:
From the above output we noticed that , the "Cust_Segment" has been writer twice, one from Left Table and another from Right Table, which suffixed by specified character vectors _L , _R. If you don't wants to display suffix, simply you can specify as suffix=c("","").
Also we can write one "Cust_Segment" from both the tables by including it in Join Columns and ignore suffix argument as follows..
>inner_join(dtCust,dtSales,by=c("Cust_Id","Cust_Segment"),copy=F)

We can also select the specific columns from Right Table instead of all columns as follows..
>inner_join(dtCust,select(dtSales,Cust_Id,FiscalQuarter,Net_Sales),by="Cust_Id",copy=F)
Note: Please make sure add Join Column in the select ()
>dtCust %>%
inner_join(select(dtSales,Cust_Id,FiscalQuarter,Net_Sales),by="Cust_Id",copy=F) %>%
group_by(Cust_Id,Cust_Name,Cust_Segment,FiscalQuarter) %>%
summarize(Net_Sales=sum(Net_Sales))

left_join() :
The left_join() function return all rows from x, and all columns from x and y. Rows in x with no match in y will have NA values in the new columns. If there are multiple matches between x and y, all combinations of the matches are returned.
Syntax :
left_join(x, y, by = "KeyVariable", copy = FALSE, suffix = c(".x", ".y"), …) Syntax :
Example :
Now we will do Left Join the above two datasets using the left_join() function as follows..
Now we will do Left Join the above two datasets using the left_join() function as follows..
>left_join(dtCust,select(dtSales,Cust_Id,FiscalQuarter,Net_Sales),by="Cust_Id",copy=F)
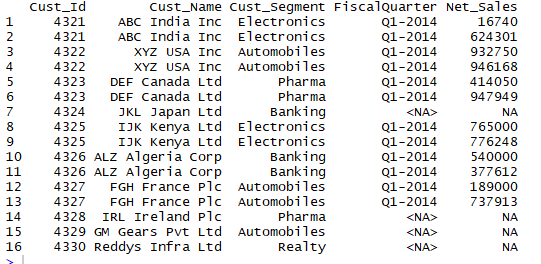
NA's have been return for the records that have no match in the right.
right_join() :
The right_join() return all rows from y, and all columns from x and y. Rows in y with no match in x will have NA values in the new columns. If there are multiple matches between x and y, all combinations of the matches are returned.
Syntax :
right_join(x, y, by = "KeyVariable", copy = FALSE, suffix = c(".x", ".y"),...)
Example :
Now we will do Right Join the above two datasets using the right_join() function as follows..
>right_join(dtCust,select(dtSales,Cust_Id,FiscalQuarter,Net_Sales),by="Cust_Id",copy=F)

full_join() :
The full_join() function return all rows and all columns from both x and y. When there are not matching values, returns NA for the one missing.
Syntax:
full_join(x, y, by = "KeyVariable", copy = FALSE, suffix = c(".x", ".y"), …)
Example :
Now we will do Full Join the above two datasets using the full_join() function as follows..
>full_join(dtCust,select(dtSales,Cust_Id,FiscalQuarter,Net_Sales),by="Cust_Id",copy=F)

Filtering joins keep the variables from the left dataframe, that having either the match or not having the match in Right dataframe.
semi_join() :The semi_join() function returns all rows from x where there are matching values in y, and keeping just columns from x.A semi join differs from an inner join because an inner join will return one row of x for each matching row of y, where a semi join will never duplicate rows of x.
Syntax:
semi_join(x, y, by = "KeyVariable", copy = FALSE, …)
Example :
Now we will do Semi Join the above two datasets using the semi_join() function as follows..
>semi_join(dtCust,dtSales,by="Cust_Id",copy=F)

anti_join() :
The anti_join() function returns all rows from x where there are no matching values in y, keeping just columns from x.
Syntax:anti_join(x, y, by = "KeyVariable", copy = FALSE, …)
Now we will do Semi Join the above two datasets using the anti_join() function as follows..
>anti_join(dtCust,dtSales,by="Cust_Id",copy=F)

III. Set Operations :
The R "dplyr" package also provides the functions union(), union_all(), intersect(), setdiff(), setequal() to perform the set operations on the data sets.
Make sure both datasets should have the same structure(Variables should be same).
The R "dplyr" package also provides the functions union(), union_all(), intersect(), setdiff(), setequal() to perform the set operations on the data sets.
Make sure both datasets should have the same structure(Variables should be same).
Example :
Suppose we have the two data sets as follows, on which we perform the set operations.
Suppose we have the two data sets as follows, on which we perform the set operations.
>dtSales1


union_all () :
The union_all() function will combine both the data sets, does not bother about duplicates.
>union_all(dtSales1,dtSales2)

union() :
The union() function will combine both the data sets, and returns the unique observations.
>union(dtSales1,dtSales2)

intersect() :
The intersect() function will returns common unique observations from both the datasets.
>intersect(dtSales1,dtSales2)
setdiff() :
The setdiff() function will returns the unique observations from left dataset, which are not part of the right data set.
>setdiff(dtSales1,dtSales2)
 >setdiff(dtSales2,dtSales1)
>setdiff(dtSales2,dtSales1)
>setdiff(dtSales1,dtSales2)

setequal() :
The setequal() function will test whether two datasets are equal or not, and return a Boolean value.
The setequal() function will test whether two datasets are equal or not, and return a Boolean value.
>setequal(dtSales1,dtSales2)
FALSE: Different number of rows
--------------------------------------------------------------------------------------------------------
Thanks, TAMATAM ; Business Intelligence & Analytics Professional
--------------------------------------------------------------------------------------------------------
Thanks, TAMATAM ; Business Intelligence & Analytics Professional
--------------------------------------------------------------------------------------------------------
No comments:
Post a Comment
Hi User, Thank You for visiting My Blog. If you wish, please share your genuine Feedback or comments only related to this Blog Posts. It is my humble request that, please do not post any Spam comments or Advertising kind of comments, which will be Ignored.