Reading, Wrangling and Writing the Tab delimited Input Data to a Text file in R
Suppose we have a Tab delimited Text Input file in below location
> filepath<-"T:/My_Tech_Lab/R_Lab/Dataframes/SalesByRegion.txt"

If we observe the data in the input file, we find that the data has headers , delimiter(separator) is tab("\t") and the Net_Sales column(Vector) having the values with comma(,) decimal.
Now we can read this files using either of the following line of code.
>mydata<-read.table(filepath,header = TRUE,sep ="\t",dec=",",numerals="warn.loss",as.is = TRUE,stringsAsFactors =FALSE)


Now the input dataframe is as follows :
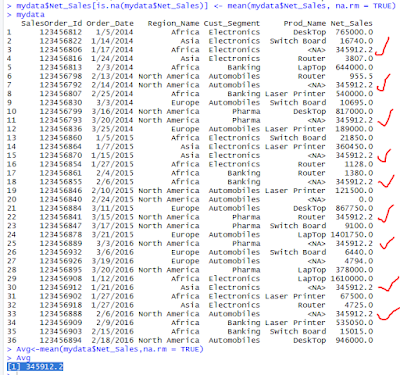
> mydata


Now we can calculate the Mean values for that variable, by ignoring the "NA" as follows..
uniqv <- na.omit(unique(x))
uniqv[which.max(tabulate(match(x, uniqv)))]
Adding a New Variable "Sales_Rating" into the Dataset :






Suppose we have a Tab delimited Text Input file in below location
> filepath<-"T:/My_Tech_Lab/R_Lab/Dataframes/SalesByRegion.txt"

If we observe the data in the input file, we find that the data has headers , delimiter(separator) is tab("\t") and the Net_Sales column(Vector) having the values with comma(,) decimal.
Now we can read this files using either of the following line of code.
>mydata<-read.table(filepath,header = TRUE,sep ="\t",dec=",",numerals="warn.loss",as.is = TRUE,stringsAsFactors =FALSE)
OR
>mydata<-read.csv(filepath,header = TRUE,sep ="\t",dec=",",numerals="warn.loss",as.is = TRUE,stringsAsFactors =FALSE)
OR
>mydata<-read.csv2(filepath,header = TRUE,sep ="\t",dec=",",numerals="warn.loss",as.is = TRUE,stringsAsFactors =FALSE)
here , as.is=TRUE property allows to read the data as it is from source, and Strings will be read as strings instead of Factors.
stringsAsFactors =FALSE , allows to read the strings as strings instead of Factors. This property will be overridden by as.is=FALSE property.
The input in the dataframe is as follows :
> mydata

The properties of the data frame is as follows..

In the above data(Observations), for the fields(Variables) we got the "NULL", "NA", "na", "" as values. We can get to know in which rows they are appearing by checking as follows..
> which(is.na(mydata$Net_Sales))
[1] 3 15 25
> which(mydata$Net_Sales=="na")
[1] 7 30
> which(mydata$Net_Sales=="NULL")
[1] 18 22
[1] 3 15 25
> which(mydata$Net_Sales=="na")
[1] 7 30
> which(mydata$Net_Sales=="NULL")
[1] 18 22
We can convert all this type of values to NA while reading from the File as follows..
mydata<-read.csv(filepath,header = TRUE,sep ="\t",dec=",",numerals="warn.loss",as.is = TRUE,stringsAsFactors =FALSE,na.strings = c("NULL","NA","na",""))
Now the input dataframe is as follows :
> mydata

Notes :
After reading the data also, you can replace/encode the values to NA using the ifelse as follows...
> mydata$Prod_Name<-ifelse(mydata$Prod_Name=="NULL"|mydata$Prod_Name=="na"|mydata$Prod_Name=="",
NA,mydata$Prod_Name)
We can know the count of NA values by each column in the entire dataframe as follows..
> colSums(is.na(mydata))SalesOrder_Id Order_Date Region_Name Cust_Segment Prod_Name Net_Sales
0 0 0 0 3 11
> sum(is.na(mydata))
[1] 14
0 0 0 0 3 11
> sum(is.na(mydata))
[1] 14
> sum(is.na(mydata$Net_Sales))
[1] 11
[1] 11
Type Conversion for a Variable(Vector) "Net_Sales" :
Since the variable "Net_Sales" having the values with Comma, they readed as character from the input file.
> typeof(mydata$Net_Sales)
[1] "character"
> class(mydata$Net_Sales)
[1] "character"
[1] "character"
> class(mydata$Net_Sales)
[1] "character"
Now we will covert this Colum to Numeric, so that we can perform any calculations on it.
>mydata$Net_Sales<-as.numeric(sub(",", "", mydata$Net_Sales, fixed = TRUE))
If we have 2 Commas in the data.. then use the below..
> mydata$Net_Sales<-as.numeric(sub(",","",sub(",", "", mydata$Net_Sales)))
Warning message:
NAs introduced by coercion
The warning message thrown because some of the missing values are there in the observations, those will be not converted.
After conversion, the observations of that variables is follows..

Now we can calculate the Mean values for that variable, by ignoring the "NA" as follows..
> Avg<-mean(mydata$Net_Sales,na.rm = TRUE)
> Avg
[1] 345912.2
Notes :
--na.rm will ignore the NA values from the mean calculation.
--R will automatically ignores the NULL values but not NA
Encoding NAs with a Mean values for a Variable(Vector) "Net_Sales" :
> Avg
[1] 345912.2
Notes :
--na.rm will ignore the NA values from the mean calculation.
--R will automatically ignores the NULL values but not NA
Encoding NAs with a Mean values for a Variable(Vector) "Net_Sales" :
If we want to replace the NAs with the Mean values for the observations in the Variable "Net_Sales", we can do that encoding as follows..
> mydata$Net_Sales[is.na(mydata$Net_Sales)] <- mean(mydata$Net_Sales, na.rm = TRUE)
Now the dataframe is looks as follows..

Notes :
If you wants to calculate the Mean by Trimming(excluding) some values in the variable, we can do it as follows..> TrimAvg<-mean(mydata$Net_Sales,trim=0.5,na.rm = TRUE)
If you wants to calculate the Mean by Trimming(excluding) some values in the variable, we can do it as follows..> TrimAvg<-mean(mydata$Net_Sales,trim=0.5,na.rm = TRUE)
here the trim=0.5 will exclude/ignores(apart from NA, if NA exists in that 5) the 5 values in beginning and 5 values at last in the Observations of the variable Net_Sales.
> TrimAvg
> TrimAvg
[1] 67500
> Avg<-mean(mydata$Net_Sales,na.rm = TRUE)
> Avg
[1] 345912.2
If you wants to calculate the Mode value, there is no direct function in R but we can calculate by defining a function as follows..
>modeval <- function(x) {> Avg
[1] 345912.2
If you wants to calculate the Mode value, there is no direct function in R but we can calculate by defining a function as follows..
uniqv <- na.omit(unique(x))
uniqv[which.max(tabulate(match(x, uniqv)))]
} >modeval(mydata$Net_Sales)
Adding a New Variable "Sales_Rating" into the Dataset :
Now we will add a new Variable "Sales_Rating" into the Dataset which calculated based on the "Net_Sales" variable as follows..
>mydata<-within ( mydata,
>mydata<-within ( mydata,
{
Sales_Rating <- NA
Sales_Rating[Net_Sales>100000]<-"Better"
Sales_Rating[Net_Sales>=50000 & Net_Sales<=100000 ]<-"Good"
Sales_Rating[Net_Sales<50000]<-"Poor"
}
)
Note :
The within() function is similar to with() function but it allows you to modify the dataframe.
Output :
 Additional Notes :
Additional Notes :
If you want to ready only specific no.of rows from the input file, use the following code :
> mydata<-read.csv(filepath,header = TRUE,sep ="\t",dec=",",numerals="warn.loss",as.is = TRUE,stringsAsFactors =FALSE,na.strings = c("NULL","NA","na",""),nrows=10)
if you want to see the beginning few rows of the data set :
>head(mydata)
if you want to see the last few rows of the data set :
>tail(mydata)
if you want to see beginning or middle 10 rows from all the columns of the data set :
>mydata[1:10,]
>mydata[10:20,]
if you want to see beginning or middle 10 rows from 3 the columns of the data set : > mydata[1:10,1:3]
> mydata[10:20,1:3]
Writing Dataset to an Output file :
Sales_Rating <- NA
Sales_Rating[Net_Sales>100000]<-"Better"
Sales_Rating[Net_Sales>=50000 & Net_Sales<=100000 ]<-"Good"
Sales_Rating[Net_Sales<50000]<-"Poor"
}
)
Note :
The within() function is similar to with() function but it allows you to modify the dataframe.
Output :

If you want to ready only specific no.of rows from the input file, use the following code :
> mydata<-read.csv(filepath,header = TRUE,sep ="\t",dec=",",numerals="warn.loss",as.is = TRUE,stringsAsFactors =FALSE,na.strings = c("NULL","NA","na",""),nrows=10)
if you want to see the beginning few rows of the data set :
>head(mydata)
if you want to see the last few rows of the data set :
>tail(mydata)
if you want to see beginning or middle 10 rows from all the columns of the data set :
>mydata[1:10,]
>mydata[10:20,]
if you want to see beginning or middle 10 rows from 3 the columns of the data set : > mydata[1:10,1:3]
> mydata[10:20,1:3]
Writing Dataset to an Output file :
We can write the data from Dataset "mydata" to various output destinations like .csv, .txt using the write.table() function.

Output path :
>opath<- "T:/My_Tech_Lab/R_Lab/Dataframes/Output/"
#Writing to .csv file with comma(,) as delimiter :
>write.table(mydata, file =paste(opath,"comOutput.csv",sep=""), append = FALSE, quote = FALSE, sep = ",", eol = "\n", na = "NA", dec = ".", row.names = FALSE, col.names = TRUE, qmethod = c("escape", "double"),fileEncoding = "")
Output :


Notes :
Next time if we writing the Output to the same destination then don't forget set the properties as follows..
append = TRUE, col.names = FALSE
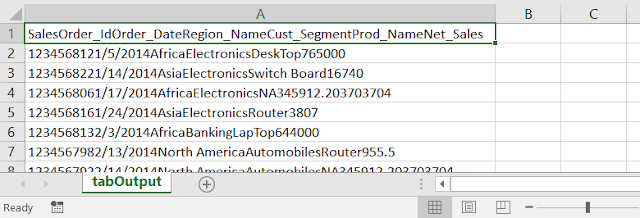
#Writing to .csv file with TAB(\t) as delimiter :
>write.table(mydata, file =paste(opath,"tabOutput.csv",sep=""), append = FALSE, quote = FALSE, sep = "\t", eol = "\n", na = "NA", dec = ".", row.names = FALSE, col.names = TRUE, qmethod = c("escape", "double"),fileEncoding = "")
Output:


Note :
In case of tab delimited output, it is written to the one column in .csv file, with \t tab delimited format. We can separate the columns using the excel Text to Columns method.
#Writing to .txt file with Comma(,) as delimiter :
>write.table(mydata, file =paste(opath,"com_Output.txt",sep=""), append = FALSE, quote = FALSE, sep = ",", eol = "\n", na = "NA", dec = ".", row.names = FALSE, col.names = TRUE, qmethod = c("escape", "double"),fileEncoding = "")
Output :


#Writing to .txt file with TAB(\t) as delimiter :
>write.table(mydata, file =paste(opath,"tab_Output.txt",sep=""), append = FALSE, quote = FALSE, sep = "\t", eol = "\n", na = "NA", dec = ".", row.names = FALSE, col.names = TRUE, qmethod = c("escape", "double"),fileEncoding = "")
Output:




--------------------------------------------------------------------------------------------------------
Thanks, TAMATAM ; Business Intelligence & Analytics Professional
--------------------------------------------------------------------------------------------------------
Thanks, TAMATAM ; Business Intelligence & Analytics Professional
--------------------------------------------------------------------------------------------------------











No comments:
Post a Comment
Hi User, Thank You for visiting My Blog. If you wish, please share your genuine Feedback or comments only related to this Blog Posts. It is my humble request that, please do not post any Spam comments or Advertising kind of comments, which will be Ignored.