Reshape or Tidying the untidy data using tidyr() Package in R
The "tidyr" is a package by Hadley Wickham that makes it easy to tidy your untidy data.
It is often used in conjunction with "dplyr" Package. Data is said to be tidy when each column represents a variable, and each row represents an observation.
The tidyr package, provides following four main functions helps to organize or reshape your data in order to make the analysis easier.
gather () :
This function converts wide data to longer format, which means collapse the columns into rows. It is analogous to the melt() function of the "reshape2" package.
This function combines two or more columns into a single column.
separate () :
This function splits one column into two or more columns.
#Installing and loading the "tidyr" and "dplyr" Packages
>install.packages("tidyr")
>library("tidyr")
>install.packages("dplyr")
>library("dplyr")
Now will discuss in detail about each of these functions using "mtcars" dataset from library "datasets"
>library(datasets)
1.gather () :
This function converts wide data to longer format, which means collapse the columns into rows. It is analogous to the melt() function of the "reshape2" package.
Syntax :
gather(data, key, value, ..., na.rm = FALSE, convert = FALSE)
here, data : the Dataframe
key, value : the Names of key and value columns to create in output
- if you want to select all variables between a and e, use a:e
- if you want to exclude a column name y use -y
Example :
We have the "mtcars" dataset as follows, where I am displaying only the head and tail rows.
 Now will add the Row names of this dataset as a New column, which we will use that in our process.
Now will add the Row names of this dataset as a New column, which we will use that in our process.
> mtcars$carmodal <- rownames(mtcars)
Now will apply the gather () , function to reshape the dataset to longer format from wider format, by gathering all the Columns(except the newly created "carmodal" column) into Rows under one column "attribute" , and the corresponding values under one column "value".
>mtcarsNew <-gather(mtcars,attribute, value, -carmodal)
OR
>mtcarsNew <- mtcars %>% gather(attribute, value, -carmodal)
Output:
Here I just displayed only the head and tail rows from gathered dataset "mtcarsNew"
 The "attribute" and "value" are the default column names given by the gather () function.
The "attribute" and "value" are the default column names given by the gather () function.
We can give our desired names for these default columns as follows..
> mtcarsNew <-gather(mtcars, key='car_attribute', value='attrib_measure', -carmodal)
Output:

We can also gather only certain columns and leave the others alone. If we want to gather all the columns from cyl to gear and leave the carb , mpg and carmodal columns as they are, we can do it as follows:
>mtcarsNew <-gather(mtcars, key='car_attribute', value='attrib_measure',cyl:gear)
OR
>mtcarsNew <-gather(mtcars,key='car_attribute', value='attrib_measure',cyl:gear,
-carmodal,-carb,-mpg)
Output:
 Note:We can gather only two columns and leave the rest of the columns as it is by this way
Note:We can gather only two columns and leave the rest of the columns as it is by this way
>mtcarsNew2 <-gather(mtcars, key='car_attribute', value='attrib_measure',c(cyl,gear))
2. spread () :



The "tidyr" is a package by Hadley Wickham that makes it easy to tidy your untidy data.
It is often used in conjunction with "dplyr" Package. Data is said to be tidy when each column represents a variable, and each row represents an observation.
The tidyr package, provides following four main functions helps to organize or reshape your data in order to make the analysis easier.
gather () :
This function converts wide data to longer format, which means collapse the columns into rows. It is analogous to the melt() function of the "reshape2" package.
spread () :
This function converts long data to wider format, which means spread the rows into columns. It is analogous to the cast() function of the "reshape2" package.
unite () : This function combines two or more columns into a single column.
separate () :
This function splits one column into two or more columns.
#Installing and loading the "tidyr" and "dplyr" Packages
>install.packages("tidyr")
>library("tidyr")
>install.packages("dplyr")
>library("dplyr")
Now will discuss in detail about each of these functions using "mtcars" dataset from library "datasets"
>library(datasets)
This function converts wide data to longer format, which means collapse the columns into rows. It is analogous to the melt() function of the "reshape2" package.
Syntax :
gather(data, key, value, ..., na.rm = FALSE, convert = FALSE)
here, data : the Dataframe
key, value : the Names of key and value columns to create in output
… : Specification of columns to gather, the allowed values are:
- variable names- if you want to select all variables between a and e, use a:e
- if you want to exclude a column name y use -y
Example :
We have the "mtcars" dataset as follows, where I am displaying only the head and tail rows.


> mtcars$carmodal <- rownames(mtcars)
Now will apply the gather () , function to reshape the dataset to longer format from wider format, by gathering all the Columns(except the newly created "carmodal" column) into Rows under one column "attribute" , and the corresponding values under one column "value".
>mtcarsNew <-gather(mtcars,attribute, value, -carmodal)
OR
>mtcarsNew <- mtcars %>% gather(attribute, value, -carmodal)
Output:
Here I just displayed only the head and tail rows from gathered dataset "mtcarsNew"

We can give our desired names for these default columns as follows..
> mtcarsNew <-gather(mtcars, key='car_attribute', value='attrib_measure', -carmodal)
Output:

We can also gather only certain columns and leave the others alone. If we want to gather all the columns from cyl to gear and leave the carb , mpg and carmodal columns as they are, we can do it as follows:
>mtcarsNew <-gather(mtcars, key='car_attribute', value='attrib_measure',cyl:gear)
OR
>mtcarsNew <-gather(mtcars,key='car_attribute', value='attrib_measure',cyl:gear,
-carmodal,-carb,-mpg)
Output:

>mtcarsNew2 <-gather(mtcars, key='car_attribute', value='attrib_measure',c(cyl,gear))
2. spread () :
This function converts long data to wider format, which means spread the rows into columns.The function spread() does the reverse of gather(). It takes two columns (key and value) and spreads into multiple columns.
It is analogous to the cast() function of the "reshape2" package.
Syntax:
spread(data, key, value, fill = NA, convert = FALSE, drop = TRUE)
Example :
We will use the gathered dataset "mtcarsNew" from above example and we apply spread()
function over it.

> mtcarsSpread<-spread(mtcarsNew, key='car_attribute', value='attrib_measure')
Output:

3. unite () :
This function combines two or more columns into a single column.Syntax:
unite(data, col, from, sep = "")
here, data: A data frame
Example :
This function combines two or more columns into a single column.Syntax:
unite(data, col, from, sep = "")
here, data: A data frame
col: The new (unquoted) name of the united column.
from: Character vector specifying the names of existing columns to be united.
sep: Separator to use between valuesExample :
First we will create a Dataset, then we will use the unite() function over it.
> set.seed(1)
> date <- as.Date('2018-01-01') + 0:14
> hour <- sample(1:24, 15)
> min <- sample(1:60, 15)
> second <- sample(1:60, 15)

unite(datehour, date, hour, sep = ' ') %>%
unite(datetime, datehour, min, second, sep = ':')
> set.seed(1)
> date <- as.Date('2018-01-01') + 0:14
> hour <- sample(1:24, 15)
> min <- sample(1:60, 15)
> second <- sample(1:60, 15)
> event <- sample(letters, 15)
> mydata <- data.frame(date, hour, min, second, event)
Now, we will combine the date, hour, min, and second columns into a new column called datetime. Usually, datetime in R is of the form Year-Month-Day Hour:Min:Second.
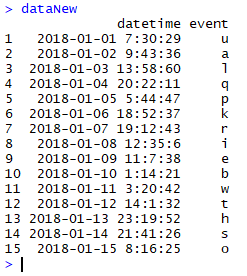
>dataNew <- mydata %>%unite(datehour, date, hour, sep = ' ') %>%
unite(datetime, datehour, min, second, sep = ':')
OR
>dataNew <- mydata %>%
unite( col='datehour', from=c(date, hour), sep = ' ') %>%
unite(col='datetime', from=c(datehour, min, second), sep = ':')
>dataNew <- mydata %>%
unite( col='datehour', from=c(date, hour), sep = ' ') %>%
unite(col='datetime', from=c(datehour, min, second), sep = ':')
Output:
4. separate () :
The function sperate() is the reverse of unite(). It takes values inside a single character column and separates them into multiple columns.
Syntax:
separate(data, col, into, sep = "[^[:alnum:]]+", remove = TRUE,convert = FALSE,
extra = "warn", fill = "warn", …)
here, data: A data frame.
col: Unquoted column names
into: Character vector specifying the names of new variables to be created.
sep: Separator between columns:
If character, is interpreted as a regular expression.
If numeric, interpreted as positions to split at. Positive values start at 1 at the far-left of the string; negative value start at -1 at the far-right of the string.
Example :
We will use the united dataset "dataNew" from above example and we apply separate()
function over it.
The function sperate() is the reverse of unite(). It takes values inside a single character column and separates them into multiple columns.
Syntax:
separate(data, col, into, sep = "[^[:alnum:]]+", remove = TRUE,convert = FALSE,
extra = "warn", fill = "warn", …)
here, data: A data frame.
col: Unquoted column names
into: Character vector specifying the names of new variables to be created.
sep: Separator between columns:
If character, is interpreted as a regular expression.
If numeric, interpreted as positions to split at. Positive values start at 1 at the far-left of the string; negative value start at -1 at the far-right of the string.
Example :
We will use the united dataset "dataNew" from above example and we apply separate()
function over it.
Now we first splits the datetime column into date and time, and then splits time into hour, min, and second.
>datasplit <- dataNew %>%
separate(datetime, c('date', 'time'), sep = ' ') %>%
separate(time, c('hour', 'min', 'second'), sep = ':')
separate(datetime, c('date', 'time'), sep = ' ') %>%
separate(time, c('hour', 'min', 'second'), sep = ':')
OR
>datasplit <- dataNew %>%
separate(col=datetime, into=c('date', 'time'), sep = ' ') %>%
separate(col=time, into=c('hour', 'min', 'second'), sep = ':')
separate(col=datetime, into=c('date', 'time'), sep = ' ') %>%
separate(col=time, into=c('hour', 'min', 'second'), sep = ':')
Output:
--------------------------------------------------------------------------------------------------------
Thanks, TAMATAM ; Business Intelligence & Analytics Professional
--------------------------------------------------------------------------------------------------------
Thanks, TAMATAM ; Business Intelligence & Analytics Professional
--------------------------------------------------------------------------------------------------------











No comments:
Post a Comment
Hi User, Thank You for visiting My Blog. If you wish, please share your genuine Feedback or comments only related to this Blog Posts. It is my humble request that, please do not post any Spam comments or Advertising kind of comments, which will be Ignored.